This post has been de-listed
It is no longer included in search results and normal feeds (front page, hot posts, subreddit posts, etc). It remains visible only via the author's post history.
So for a long while there's been hype about GME swaps. People are posting screenshots with no headers or are showing a partial view of the data. If there are headers, the columns are often renamed etc.
This makes it very difficult to find a common understanding. I hope to clear up some of this confusion, if not all of it.
Data Sources and Definitions
So, first of all, if you don't already know -- the swap data is all publicly available from the DTCC. This is a result of the Dodd Frank act after the 2008 global market crash.
https://pddata.dtcc.com/ppd/secdashboard
If you click on CUMULATIVE REPORTS at the top, and then EQUITIES in the second tab row, this is the data source that people are pulling swap information from.
It contains every single swap that has been traded, collected daily. Downloading them one by one though would be insane, and that's where python comes into play (or really any programming language you want, python is just easy... even for beginners!)
Automating Data Collection
We can write a simply python script that downloads every single file for us:
import requests
import datetime
# Generate daily dates from two years ago to today
start = datetime.datetime.today() - datetime.timedelta(days=730)
end = datetime.datetime.today()
dates = [start datetime.timedelta(days=i) for i in range((end - start).days 1)]
# Generate filenames for each date
filenames = [
f"SEC_CUMULATIVE_EQUITIES_{year}_{month}_{day}.zip"
for year, month, day in [
(date.strftime("%Y"), date.strftime("%m"), date.strftime("%d"))
for date in dates
]
]
# Download files
for filename in filenames:
url = f"https://pddata.dtcc.com/ppd/api/report/cumulative/sec/{filename}"
req = requests.get(url)
if req.status_code != 200:
print(f"Failed to download {url}")
continue
zip_filename = url.split("/")[-1]
with open(zip_filename, "wb") as f:
f.write(req.content)
print(f"Downloaded and saved {zip_filename}")
However, the data that is published by this system isn't meant for humans to consume directly, it's meant to be processed by an application that would then, presumably, make it easier for people to understand. Unfortunately we have no system, so we're left trying to decipher the raw data.
Deciphering the Data
Luckily, they published documentation!
https://www.cftc.gov/media/6576/Part43_45TechnicalSpecification093021CLEAN/download
There's going to be a lot of technical financial information in that documentation. Good sources to learn about what they mean are:
https://www.investopedia.com/ https://dtcclearning.com/
Also, the documentation makes heavy use of ISO 20022 Codes to standardize codes for easy consumption by external systems. Here is a reference of what all the codes mean if they're not directly defined in the documentation.
https://www.iso20022.org/sites/default/files/media/file/ExternalCodeSets_XLSX.zip
With that in mind, we can finally start looking into some GME swap data.
Full Automation of Data Retrieval and Processing
First, we'll need to set up an environment. If you're new to python, it's probably easiest to use Anaconda. It comes with all the packages you'll need out of the box.
https://www.anaconda.com/download/success
EDIT: I've added this code to a github repo if you'd prefer to pull the code down that way. Feel free to submit PR's if you'd like or just fork and go nuts! https://github.com/DustinReddit/GME-Swaps
Otherwise, feel free to set up a virtual environment and install these packages:
certifi==2024.7.4
charset-normalizer==3.3.2
idna==3.7
numpy==2.0.0
pandas==2.2.2
python-dateutil==2.9.0.post0
pytz==2024.1
requests==2.32.3
six==1.16.0
tqdm==4.66.4
tzdata==2024.1
urllib3==2.2.2
Now you can create a file named swaps.py (or whatever you want)
I've modified the python snippet above to efficiently grab and process all the data from the DTCC.
import pandas as pd
import numpy as np
import glob
import requests
import os
from zipfile import ZipFile
import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
# Define some configuration variables
OUTPUT_PATH = r"./output" # path to folder where you want filtered reports to save
MAX_WORKERS = 16 # number of threads to use for downloading and filtering
executor = ThreadPoolExecutor(max_workers=MAX_WORKERS)
# Generate daily dates from two years ago to today
start = datetime.datetime.today() - datetime.timedelta(days=730)
end = datetime.datetime.today()
dates = [start datetime.timedelta(days=i) for i in range((end - start).days 1)]
# Generate filenames for each date
filenames = [
f"SEC_CUMULATIVE_EQUITIES_{year}_{month}_{day}.zip"
for year, month, day in [
(date.strftime("%Y"), date.strftime("%m"), date.strftime("%d"))
for date in dates
]
]
def download_and_filter(filename):
url = f"https://pddata.dtcc.com/ppd/api/report/cumulative/sec/{filename}"
req = requests.get(url)
if req.status_code != 200:
print(f"Failed to download {url}")
return
with open(filename, "wb") as f:
f.write(req.content)
# Extract csv from zip
with ZipFile(filename, "r") as zip_ref:
csv_filename = zip_ref.namelist()[0]
zip_ref.extractall()
# Load content into dataframe
df = pd.read_csv(csv_filename, low_memory=False, on_bad_lines="skip")
# Perform some filtering and restructuring of pre 12/04/22 reports
if "Primary Asset Class" in df.columns or "Action Type" in df.columns:
df = df[
df["Underlying Asset ID"].str.contains(
"GME.N|GME.AX|US36467W1099|36467W109", na=False
)
]
else:
df = df[
df["Underlier ID-Leg 1"].str.contains(
"GME.N|GME.AX|US36467W1099|36467W109", na=False
)
]
# Save the dataframe as CSV
output_filename = os.path.join(OUTPUT_PATH, f"{csv_filename}")
df.to_csv(output_filename, index=False)
# Delete original downloaded files
os.remove(filename)
os.remove(csv_filename)
tasks = []
for filename in filenames:
tasks.append(executor.submit(download_and_filter, filename))
for task in tqdm(as_completed(tasks), total=len(tasks)):
pass
files = glob.glob(OUTPUT_PATH "/" "*")
# Ignore "filtered.csv" file
files = [file for file in files if "filtered" not in file]
def filter_merge():
master = pd.DataFrame() # Start with an empty dataframe
for file in files:
df = pd.read_csv(file, low_memory=False)
# Skip file if the dataframe is empty, meaning it contained only column names
if df.empty:
continue
# Check if there is a column named "Dissemination Identifier"
if "Dissemination Identifier" not in df.columns:
# Rename "Dissemintation ID" to "Dissemination Identifier" and "Original Dissemintation ID" to "Original Dissemination Identifier"
df.rename(
columns={
"Dissemintation ID": "Dissemination Identifier",
"Original Dissemintation ID": "Original Dissemination Identifier",
},
inplace=True,
)
master = pd.concat([master, df], ignore_index=True)
return master
master = filter_merge()
# Treat "Original Dissemination Identifier" and "Dissemination Identifier" as long integers
master["Original Dissemination Identifier"] = master[
"Original Dissemination Identifier"
].astype("Int64")
master["Dissemination Identifier"] = master["Dissemination Identifier"].astype("Int64")
master = master.drop(columns=["Unnamed: 0"], errors="ignore")
master.to_csv(
r"output/filtered.csv"
) # replace with desired path for successfully filtered and merged report
# Sort by "Event timestamp"
master = master.sort_values(by="Event timestamp")
"""
This df represents a log of all the swaps transactions that have occurred in the past two years.
Each row represents a single transaction. Swaps are correlated by the "Dissemination ID" column. Any records that
that have an "Original Dissemination ID" are modifications of the original swap. The "Action Type" column indicates
whether the record is an original swap, a modification (or correction), or a termination of the swap.
We want to split up master into a single dataframe for each swap. Each dataframe will contain the original swap and
all correlated modifications and terminations. The dataframes will be saved as CSV files in the 'output_swaps' folder.
"""
# Create a list of unique Dissemination IDs that have an empty "Original Dissemination ID" column or is NaN
unique_ids = master[
master["Original Dissemination Identifier"].isna()
| (master["Original Dissemination Identifier"] == "")
]["Dissemination Identifier"].unique()
# Add unique Dissemination IDs that are in the "Original Dissemination ID" column
unique_ids = np.append(
unique_ids,
master["Original Dissemination Identifier"].unique(),
)
# filter out NaN from unique_ids
unique_ids = [int(x) for x in unique_ids if not np.isnan(x)]
# Remove duplicates
unique_ids = list(set(unique_ids))
# For each unique Dissemination ID, filter the master dataframe to include all records with that ID
# in the "Original Dissemination ID" column
open_swaps = pd.DataFrame()
for unique_id in tqdm(unique_ids):
# Filter master dataframe to include all records with the unique ID in the "Dissemination ID" column
swap = master[
(master["Dissemination Identifier"] == unique_id)
| (master["Original Dissemination Identifier"] == unique_id)
]
# Determine if the swap was terminated. Terminated swaps will have a row with a value of "TERM" in the "Event Type" column.
was_terminated = (
"TERM" in swap["Action type"].values or "ETRM" in swap["Event type"].values
)
if not was_terminated:
open_swaps = pd.concat([open_swaps, swap], ignore_index=True)
# Save the filtered dataframe as a CSV file
output_filename = os.path.join(
OUTPUT_PATH,
"processed",
f"{'CLOSED' if was_terminated else 'OPEN'}_{unique_id}.csv",
)
swap.to_csv(
output_filename,
index=False,
) # replace with desired path for successfully filtered and merged report
output_filename = os.path.join(
OUTPUT_PATH, "processed", "output/processed/OPEN_SWAPS.csv"
)
open_swaps.to_csv(output_filename, index=False)
Note that I set MAX_WORKS at the top of the script to 16. This nearly maxed out the 64GB of RAM on my machine. You should lower it if you run into out of memory issues... if you have an absolute beast of a machine, feel free to increase it!
The Data
If you prefer not to do all of that yourself and do, in fact, trust me bro, then I've uploaded a copy of the data as of yesterday, June 18th, here:
https://file.io/rK9d0yRU8Had (Link dead already I guess?)
https://drive.google.com/file/d/1Czku_HSYn_SGCBOPyTuyRyTixwjfkp6x/view?usp=sharing
Overview of the Output from the Data Retrieval Script
So, the first thing we need to understand about the swaps data is that the records are stored in a format known as a "log structured database". That is, in the DTCC system, no records are ever modified. Records are always added to the end of the list.
This gives us a way of seeing every single change that has happened over the lifetime of the data.
Correlating Records into Individual Swaps
We correlate related entries through two fields: Dissemination Identifier and Original Dissemination Identifier
Because we only have a subset of the full data, we can identify unique swaps in two ways:
- A record that has a
Dissemination Identifier, a blankOriginal Dissemination Identifierand anAction typeofNEWT-- this is a newly opened swap. - A record that has an
Original Dissemination Identifierthat isn't present in theDissemination Identifiercolumn
The latter represents two different scenarios as far as I can tell, that is -- either the swap was created before the earliest date we could fetch from the DTCC or when the swap was created it didn't originally contain GME.
The Lifetime of a Swap
Going back to the Technical Documentation, toward the end of that document is a number of examples that walk through different scenarios.
The gist, however is that all swaps begin with an Action type of NEWT (new trade) and end with an Action type of TERM (terminated).
We finally have all the information we need to track the swaps.
The Files in the Output Directory
Since we are able to track all of the swaps individually, I broke out every swap into its own file for reference. The filename starts with CLOSED if I could clearly find a TERM record for the swap. This definitively tells us that particular swap is closed.
All other swaps are presumed to be open and are prepended with OPEN.
NOTE: That doesn't necessarily mean that the swap is still active against GME, however. For an example, if the swap represents a basket swap, GME could have been rotated out of the basket and we would be missing that record.
For convenience, I also aggregated all of the open swaps into a file named OPEN_SWAPS.csv
Understanding a Swap
Finally, we're brought to looking at the individual swaps. As a simple example, consider swap 1001660943.
We can sort by the Event timestamp to get the order of the records and when they occurred.
https://i.postimg.cc/cLH8VFhX/image.png
{kind=link}
In this case, we can see that the swap was opened on May 16 and closed on May 21.
Next, we can see that the Notional amount of the swap was $300,000 at Open and $240,000 at close.
https://i.postimg.cc/B6gSZ0QD/image.png
{kind=link}
Next, we see that the Price of GME when the swap was entered was $27.67 (the long value is probably due to some rounding errors with floating point numbers), that they're representing the Price as price per share SHAS, and then Spread-Leg 1 and Spread-Leg 2
https://i.postimg.cc/bw9p9Pk5/image.png
{kind=link}
So, for those values, let's reference the DTCC documentation.
https://i.postimg.cc/6pj1X1X3/image.png
{kind=link}
Okay, so these values represent the interest rate that the receiver will be paying, but to interpret these values, we need to look at the Spread Notation
https://i.postimg.cc/8PTyrVkc/image.png
{kind=link}
We see there is a Spread Notation of 3, and that it represents a decimal representation. So, the interest rate is 0.25%
Next, we see a Floating rate day count convention
https://i.postimg.cc/xTHzYkVb/image.png
{kind=link}
Without going to screenshot all the docs and everything, the documentation says that A004 is an ISO 20022 Code that represents how the interest will be calculated. Looking up A004 in the ISO 20022 Codes I provided above shows that interest is calculated as ACT/360.
We can then look up ACT/360 in Investopedia, which brings us here: https://www.investopedia.com/terms/d/daycount.asp
actual/360 - calculates the daily interest using a 360-day year and then multiplies that by the actual number of days in each time period.
So the daily interest on this swap is 0.25% / 360 = 0.000695%
Next, we see that payments are made monthly on this swap.
https://i.postimg.cc/j5VppkHf/image.png
{kind=link}
Finally, we see that the type of instrument we're looking at is a Single Stock Total Return Swap
https://i.postimg.cc/YCYfXnCZ/image.png
{kind=link}
Conclusions
So, I don't want to go into another "trust me bro" on this (yet), but rather I wanted to help demystify a lot of the information going around about this swap data.
With all of that in mind, I wanted to bring to attention a couple things I've noticed generally about this data.
The first of which is that it's common to see swaps that have tons of entries with an Action type of MODI. According to the documentation, that is a modification of the terms of the swap.
https://i.postimg.cc/cJJ7ssmy/image.png
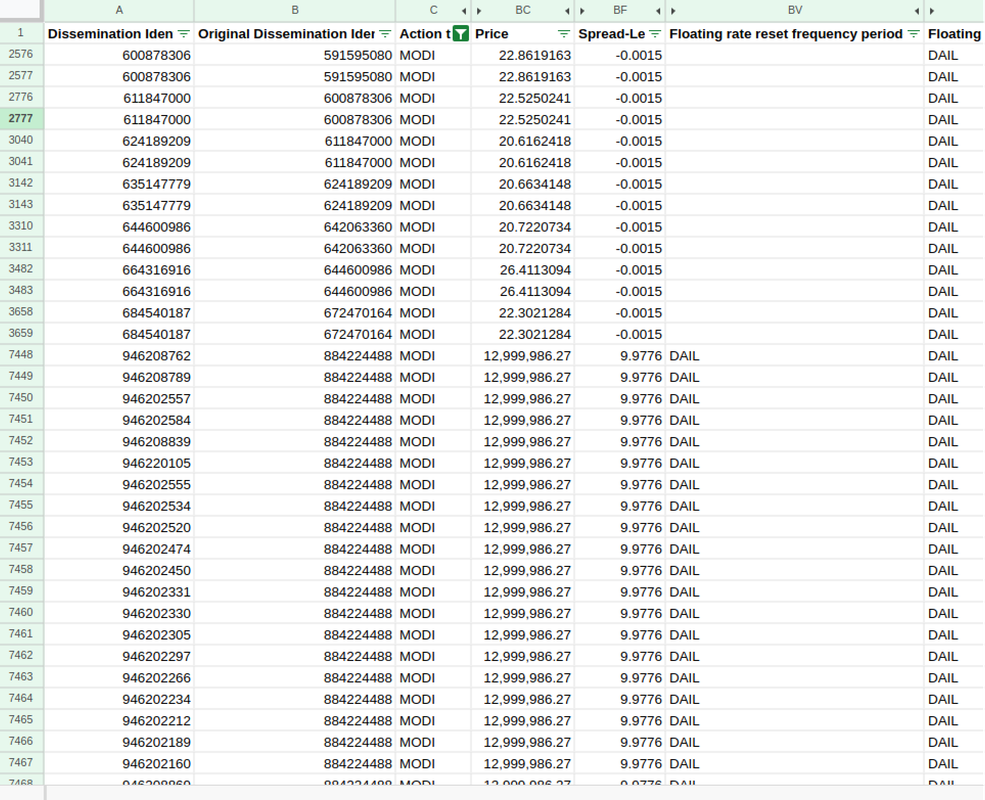{kind=link}
This screenshot, for instance, shows a couple swaps that have entry after entry of MODI type transactions. This is because their interest is calculated and collected daily. So every single day at market close they'll negotiate a new interest rate and/or notional value (depending on the type of swap).
Other times, they'll agree to swap out the underlyings in a basket swap in order to keep their payments the same.
Regardless, it's absolutely clear that simply adding up the notional values is wrong.
I hope this clears up some of the confusion around the swap data and that someone finds this useful.
Update @ 7/19/2024
So, for those of you that are familiar with github, I added another script to denoise the open swap data and filter all but the most recent transaction for every open swap I could identify.
NOTE: Like I mentioned above, these open swaps could potentially be "closed" with respect to GME, particularly the basket swaps, as GME could have been rotated out of the basket and so we would be missing that transaction with the data we've collected so far.
Here is that script: https://github.com/DustinReddit/GME-Swaps/blob/master/analysis.py
Here is a google sheets of the data that was extracted:
https://docs.google.com/spreadsheets/d/1N2aFUWJe6Z5Q8t01BLQ5eVQ5RmXb9_snTnWBuXyTHtA/edit?usp=sharing
And if you just want the csv, here's a link to that:
https://drive.google.com/file/d/16cAP1LxsNq_as6xcTJ7Wi5AGlloWdGaH/view?usp=sharing
Again, I'm going to refrain from drawing any conclusions for the time being. I just want to work toward getting an accurate representation of the current situation based on the publicly available data.
Please, please, please feel free to dig in and let's see if we can collectively work toward a better understanding!
Finally, I just wanted to give a big thank you to everyone that's taken the time to look at this. I think we can make a huge step forward together!
Subreddit
Post Details
- Posted
- 3 months ago
- Reddit URL
- View post on reddit.com
- External URL
- reddit.com/r/Superstonk/...